
Author: Jason Brownlee
Semi-supervised learning is the challenging problem of training a classifier in a dataset that contains a small number of labeled examples and a much larger number of unlabeled examples.
The Generative Adversarial Network, or GAN, is an architecture that makes effective use of large, unlabeled datasets to train an image generator model via an image discriminator model. The discriminator model can be used as a starting point for developing a classifier model in some cases.
The semi-supervised GAN, or SGAN, model is an extension of the GAN architecture that involves the simultaneous training of a supervised discriminator, unsupervised discriminator, and a generator model. The result is both a supervised classification model that generalizes well to unseen examples and a generator model that outputs plausible examples of images from the domain.
In this tutorial, you will discover how to develop a Semi-Supervised Generative Adversarial Network from scratch.
After completing this tutorial, you will know:
- The semi-supervised GAN is an extension of the GAN architecture for training a classifier model while making use of labeled and unlabeled data.
- There are at least three approaches to implementing the supervised and unsupervised discriminator models in Keras used in the semi-supervised GAN.
- How to train a semi-supervised GAN from scratch on MNIST and load and use the trained classifier for making predictions.
Discover how to develop DCGANs, conditional GANs, Pix2Pix, CycleGANs, and more with Keras in my new GANs book, with 29 step-by-step tutorials and full source code.
Let’s get started.

How to Implement a Semi-Supervised Generative Adversarial Network From Scratch.
Photo by Carlos Johnson, some rights reserved.
Tutorial Overview
This tutorial is divided into four parts; they are:
- What Is the Semi-Supervised GAN?
- How to Implement the Semi-Supervised Discriminator Model
- How to Develop a Semi-Supervised GAN for MNIST
- How to Load and Use the Final SGAN Classifier Model
What Is the Semi-Supervised GAN?
Semi-supervised learning refers to a problem where a predictive model is required and there are few labeled examples and many unlabeled examples.
The most common example is a classification predictive modeling problem in which there may be a very large dataset of examples, but only a small fraction have target labels. The model must learn from the small set of labeled examples and somehow harness the larger dataset of unlabeled examples in order to generalize to classifying new examples in the future.
The Semi-Supervised GAN, or sometimes SGAN for short, is an extension of the Generative Adversarial Network architecture for addressing semi-supervised learning problems.
One of the primary goals of this work is to improve the effectiveness of generative adversarial networks for semi-supervised learning (improving the performance of a supervised task, in this case, classification, by learning on additional unlabeled examples).
— Improved Techniques for Training GANs, 2016.
The discriminator in a traditional GAN is trained to predict whether a given image is real (from the dataset) or fake (generated), allowing it to learn features from unlabeled images. The discriminator can then be used via transfer learning as a starting point when developing a classifier for the same dataset, allowing the supervised prediction task to benefit from the unsupervised training of the GAN.
In the Semi-Supervised GAN, the discriminator model is updated to predict K+1 classes, where K is the number of classes in the prediction problem and the additional class label is added for a new “fake” class. It involves directly training the discriminator model for both the unsupervised GAN task and the supervised classification task simultaneously.
We train a generative model G and a discriminator D on a dataset with inputs belonging to one of N classes. At training time, D is made to predict which of N+1 classes the input belongs to, where an extra class is added to correspond to the outputs of G.
— Semi-Supervised Learning with Generative Adversarial Networks, 2016.
As such, the discriminator is trained in two modes: a supervised and unsupervised mode.
- Unsupervised Training: In the unsupervised mode, the discriminator is trained in the same way as the traditional GAN, to predict whether the example is either real or fake.
- Supervised Training: In the supervised mode, the discriminator is trained to predict the class label of real examples.
Training in unsupervised mode allows the model to learn useful feature extraction capabilities from a large unlabeled dataset, whereas training in supervised mode allows the model to use the extracted features and apply class labels.
The result is a classifier model that can achieve state-of-the-art results on standard problems such as MNIST when trained on very few labeled examples, such as tens, hundreds, or one thousand. Additionally, the training process can also result in better quality images output by the generator model.
For example, Augustus Odena in his 2016 paper titled “Semi-Supervised Learning with Generative Adversarial Networks” shows how a GAN-trained classifier is able to perform as well as or better than a standalone CNN model on the MNIST handwritten digit recognition task when trained with 25, 50, 100, and 1,000 labeled examples.
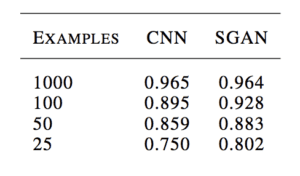
Example of the Table of Results Comparing Classification Accuracy of a CNN and SGAN on MNIST.
Taken from: Semi-Supervised Learning with Generative Adversarial Networks
Tim Salimans, et al. from OpenAI in their 2016 paper titled “Improved Techniques for Training GANs” achieved at the time state-of-the-art results on a number of image classification tasks using a semi-supervised GAN, including MNIST.

Example of the Table of Results Comparing Classification Accuracy of other GAN models to a SGAN on MNIST.
Taken From: Improved Techniques for Training GANs
Want to Develop GANs from Scratch?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
How to Implement the Semi-Supervised Discriminator Model
There are a number of ways that we can implement the discriminator model for the semi-supervised GAN.
In this section, we will review three candidate approaches.
Traditional Discriminator Model
Consider a discriminator model for the standard GAN model.
It must take an image as input and predict whether it is real or fake. More specifically, it predicts the likelihood of the input image being real. The output layer uses a sigmoid activation function to predict a probability value in [0,1] and the model is typically optimized using a binary cross entropy loss function.
For example, we can define a simple discriminator model that takes grayscale images as input with the size of 28×28 pixels and predicts a probability of the image being real. We can use best practices and downsample the image using convolutional layers with a 2×2 stride and a leaky ReLU activation function.
The define_discriminator() function below implements this and defines our standard discriminator model.
# example of defining the discriminator model from keras.models import Model from keras.layers import Input from keras.layers import Dense from keras.layers import Conv2D from keras.layers import LeakyReLU from keras.layers import Dropout from keras.layers import Flatten from keras.optimizers import Adam from keras.utils.vis_utils import plot_model # define the standalone discriminator model def define_discriminator(in_shape=(28,28,1)): # image input in_image = Input(shape=in_shape) # downsample fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(in_image) fe = LeakyReLU(alpha=0.2)(fe) # downsample fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe) fe = LeakyReLU(alpha=0.2)(fe) # downsample fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe) fe = LeakyReLU(alpha=0.2)(fe) # flatten feature maps fe = Flatten()(fe) # dropout fe = Dropout(0.4)(fe) # output layer d_out_layer = Dense(1, activation='sigmoid')(fe) # define and compile discriminator model d_model = Model(in_image, d_out_layer) d_model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5)) return d_model # create model model = define_discriminator() # plot the model plot_model(model, to_file='discriminator_plot.png', show_shapes=True, show_layer_names=True)
Running the example creates a plot of the discriminator model, clearly showing the 28x28x1 shape of the input image and the prediction of a single probability value.

Plot of a Standard GAN Discriminator Model
Separate Discriminator Models With Shared Weights
Starting with the standard GAN discriminator model, we can update it to create two models that share feature extraction weights.
Specifically, we can define one classifier model that predicts whether an input image is real or fake, and a second classifier model that predicts the class of a given model.
- Binary Classifier Model. Predicts whether the image is real or fake, sigmoid activation function in the output layer, and optimized using the binary cross entropy loss function.
- Multi-Class Classifier Model. Predicts the class of the image, softmax activation function in the output layer, and optimized using the categorical cross entropy loss function.
Both models have different output layers but share all feature extraction layers. This means that updates to one of the classifier models will impact both models.
The example below creates the traditional discriminator model with binary output first, then re-uses the feature extraction layers and creates a new multi-class prediction model, in this case with 10 classes.
# example of defining semi-supervised discriminator model from keras.models import Model from keras.layers import Input from keras.layers import Dense from keras.layers import Conv2D from keras.layers import LeakyReLU from keras.layers import Dropout from keras.layers import Flatten from keras.optimizers import Adam from keras.utils.vis_utils import plot_model # define the standalone supervised and unsupervised discriminator models def define_discriminator(in_shape=(28,28,1), n_classes=10): # image input in_image = Input(shape=in_shape) # downsample fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(in_image) fe = LeakyReLU(alpha=0.2)(fe) # downsample fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe) fe = LeakyReLU(alpha=0.2)(fe) # downsample fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe) fe = LeakyReLU(alpha=0.2)(fe) # flatten feature maps fe = Flatten()(fe) # dropout fe = Dropout(0.4)(fe) # unsupervised output d_out_layer = Dense(1, activation='sigmoid')(fe) # define and compile unsupervised discriminator model d_model = Model(in_image, d_out_layer) d_model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5)) # supervised output c_out_layer = Dense(n_classes, activation='softmax')(fe) # define and compile supervised discriminator model c_model = Model(in_image, c_out_layer) c_model.compile(loss='sparse_categorical_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5), metrics=['accuracy']) return d_model, c_model # create model d_model, c_model = define_discriminator() # plot the model plot_model(d_model, to_file='discriminator1_plot.png', show_shapes=True, show_layer_names=True) plot_model(c_model, to_file='discriminator2_plot.png', show_shapes=True, show_layer_names=True)
Running the example creates and plots both models.
The plot for the first model is the same as before.

Plot of an Unsupervised Binary Classification GAN Discriminator Model
The plot of the second model shows the same expected input shape and same feature extraction layers, with a new 10 class classification output layer.

Plot of a Supervised Multi-Class Classification GAN Discriminator Model
Single Discriminator Model With Multiple Outputs
Another approach to implementing the semi-supervised discriminator model is to have a single model with multiple output layers.
Specifically, this is a single model with one output layer for the unsupervised task and one output layer for the supervised task.
This is like having separate models for the supervised and unsupervised tasks in that they both share the same feature extraction layers, except that in this case, each input image always has two output predictions, specifically a real/fake prediction and a supervised class prediction.
A problem with this approach is that when the model is updated unlabeled and generated images, there is no supervised class label. In that case, these images must have an output label of “unknown” or “fake” from the supervised output. This means that an additional class label is required for the supervised output layer.
The example below implements the multi-output single model approach for the discriminator model in the semi-supervised GAN architecture.
We can see that the model is defined with two output layers and that the output layer for the supervised task is defined with n_classes + 1. in this case 11, making room for the additional “unknown” class label.
We can also see that the model is compiled to two loss functions, one for each output layer of the model.
# example of defining semi-supervised discriminator model from keras.models import Model from keras.layers import Input from keras.layers import Dense from keras.layers import Conv2D from keras.layers import LeakyReLU from keras.layers import Dropout from keras.layers import Flatten from keras.optimizers import Adam from keras.utils.vis_utils import plot_model # define the standalone supervised and unsupervised discriminator models def define_discriminator(in_shape=(28,28,1), n_classes=10): # image input in_image = Input(shape=in_shape) # downsample fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(in_image) fe = LeakyReLU(alpha=0.2)(fe) # downsample fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe) fe = LeakyReLU(alpha=0.2)(fe) # downsample fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe) fe = LeakyReLU(alpha=0.2)(fe) # flatten feature maps fe = Flatten()(fe) # dropout fe = Dropout(0.4)(fe) # unsupervised output d_out_layer = Dense(1, activation='sigmoid')(fe) # supervised output c_out_layer = Dense(n_classes + 1, activation='softmax')(fe) # define and compile supervised discriminator model model = Model(in_image, [d_out_layer, c_out_layer]) model.compile(loss=['binary_crossentropy', 'sparse_categorical_crossentropy'], optimizer=Adam(lr=0.0002, beta_1=0.5), metrics=['accuracy']) return model # create model model = define_discriminator() # plot the model plot_model(model, to_file='multioutput_discriminator_plot.png', show_shapes=True, show_layer_names=True)
Running the example creates and plots the single multi-output model.
The plot clearly shows the shared layers and the separate unsupervised and supervised output layers.
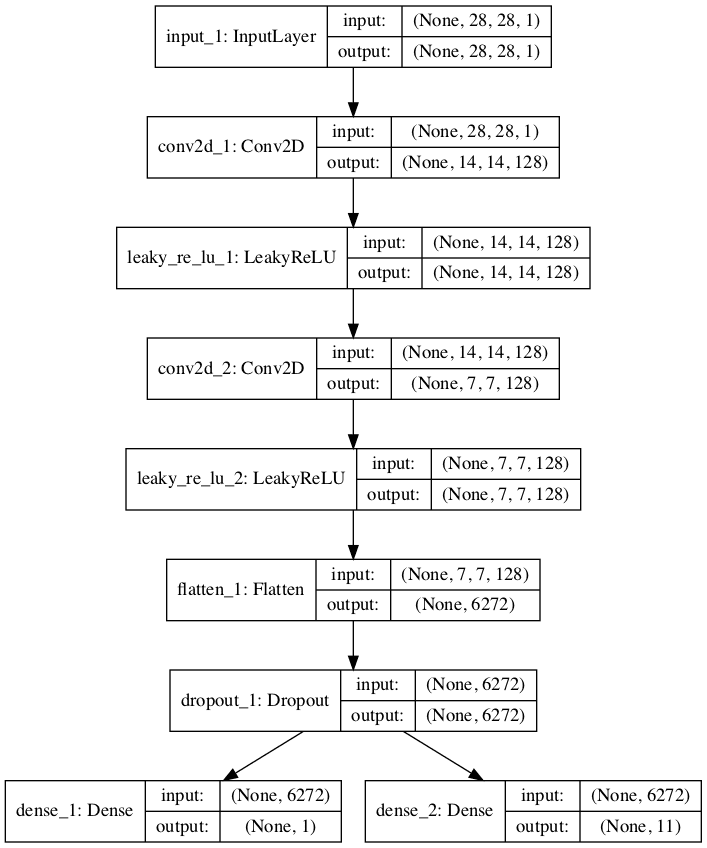
Plot of a Semi-Supervised GAN Discriminator Model With Unsupervised and Supervised Output Layers
Stacked Discriminator Models With Shared Weights
A final approach is very similar to the prior two approaches and involves creating separate logical unsupervised and supervised models but attempts to reuse the output layers of one model to feed as input into another model.
The approach is based on the definition of the semi-supervised model in the 2016 paper by Tim Salimans, et al. from OpenAI titled “Improved Techniques for Training GANs.”
In the paper, they describe an efficient implementation, where first the supervised model is created with K output classes and a softmax activation function. The unsupervised model is then defined that takes the output of the supervised model prior to the softmax activation, then calculates a normalized sum of the exponential outputs.
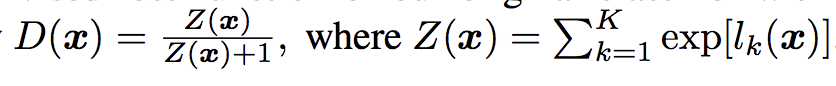
Example of the Output Function for the Unsupervised Discriminator Model in the SGAN.
Taken from: Improved Techniques for Training GANs
To make this clearer, we can implement this activation function in NumPy and run some sample activations through it to see what happens.
The complete example is listed below.
# example of custom activation function import numpy as np # custom activation function def custom_activation(output): logexpsum = np.sum(np.exp(output)) result = logexpsum / (logexpsum + 1.0) return result # all -10s output = np.asarray([-10.0, -10.0, -10.0]) print(custom_activation(output)) # all -1s output = np.asarray([-1.0, -1.0, -1.0]) print(custom_activation(output)) # all 0s output = np.asarray([0.0, 0.0, 0.0]) print(custom_activation(output)) # all 1s output = np.asarray([1.0, 1.0, 1.0]) print(custom_activation(output)) # all 10s output = np.asarray([10.0, 10.0, 10.0]) print(custom_activation(output))
Remember, the output of the unsupervised model prior to the softmax activation function will be the activations of the nodes directly. They will be small positive or negative values, but not normalized, as this would be performed by the softmax activation.
The custom activation function will output a value between 0.0 and 1.0.
A value close to 0.0 is output for a small or negative activation and a value close to 1.0 for a positive or large activation. We can see this when we run the example.
0.00013618124143106674 0.5246331135813284 0.75 0.890768227426964 0.9999848669190928
This means that the model is encouraged to output a strong class prediction for real examples, and a small class prediction or low activation for fake examples. It’s a clever trick and allows the re-use of the same output nodes from the supervised model in both models.
The activation function can be implemented almost directly via the Keras backend and called from a Lambda layer, e.g. a layer that will apply a custom function to the input to the layer.
The complete example is listed below. First, the supervised model is defined with a softmax activation and categorical cross entropy loss function. The unsupervised model is stacked on top of the output layer of the supervised model before the softmax activation, and the activations of the nodes pass through our custom activation function via the Lambda layer.
No need for a sigmoid activation function as we have already normalized the activation. As before, the unsupervised model is fit using binary cross entropy loss.
# example of defining semi-supervised discriminator model
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers import Conv2D
from keras.layers import LeakyReLU
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers import Activation
from keras.layers import Lambda
from keras.optimizers import Adam
from keras.utils.vis_utils import plot_model
from keras import backend
# custom activation function
def custom_activation(output):
logexpsum = backend.sum(backend.exp(output), axis=-1, keepdims=True)
result = logexpsum / (logexpsum + 1.0)
return result
# define the standalone supervised and unsupervised discriminator models
def define_discriminator(in_shape=(28,28,1), n_classes=10):
# image input
in_image = Input(shape=in_shape)
# downsample
fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(in_image)
fe = LeakyReLU(alpha=0.2)(fe)
# downsample
fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe)
fe = LeakyReLU(alpha=0.2)(fe)
# downsample
fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe)
fe = LeakyReLU(alpha=0.2)(fe)
# flatten feature maps
fe = Flatten()(fe)
# dropout
fe = Dropout(0.4)(fe)
# output layer nodes
fe = Dense(n_classes)(fe)
# supervised output
c_out_layer = Activation('softmax')(fe)
# define and compile supervised discriminator model
c_model = Model(in_image, c_out_layer)
c_model.compile(loss='sparse_categorical_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5), metrics=['accuracy'])
# unsupervised output
d_out_layer = Lambda(custom_activation)(fe)
# define and compile unsupervised discriminator model
d_model = Model(in_image, d_out_layer)
d_model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5))
return d_model, c_model
# create model
d_model, c_model = define_discriminator()
# plot the model
plot_model(d_model, to_file='stacked_discriminator1_plot.png', show_shapes=True, show_layer_names=True)
plot_model(c_model, to_file='stacked_discriminator2_plot.png', show_shapes=True, show_layer_names=True)
Running the example creates and plots the two models, which look much the same as the two models in the first example.
Stacked version of the unsupervised discriminator model:
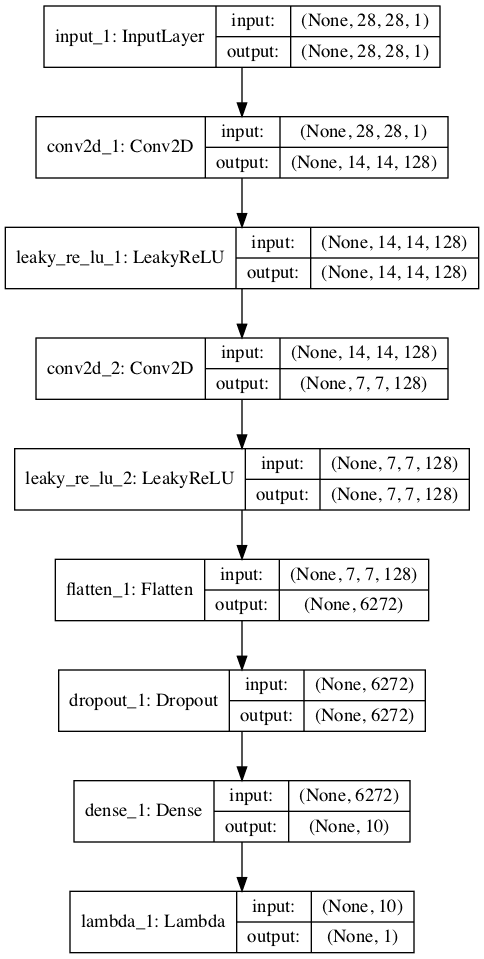
Plot of the Stacked Version of the Unsupervised Discriminator Model of the Semi-Supervised GAN
Stacked version of the supervised discriminator model:
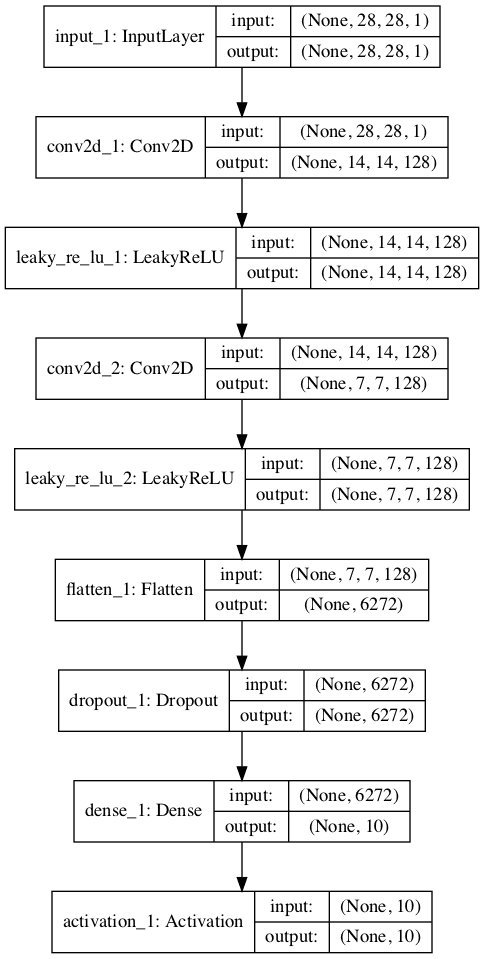
Plot of the Stacked Version of the Supervised Discriminator Model of the Semi-Supervised GAN
Now that we have seen how to implement the discriminator model in the semi-supervised GAN, we can develop a complete example for image generation and semi-supervised classification.
How to Develop a Semi-Supervised GAN for MNIST
In this section, we will develop a semi-supervised GAN model for the MNIST handwritten digit dataset.
The dataset has 10 classes for the digits 0-9, therefore the classifier model will have 10 output nodes. The model will be fit on the training dataset that contains 60,000 examples. Only 100 of the images in the training dataset will be used with labels, 10 from each of the 10 classes.
We will start off by defining the models.
We will use the stacked discriminator model, exactly as defined in the previous section.
Next, we can define the generator model. In this case, the generator model will take as input a point in the latent space and will use transpose convolutional layers to output a 28×28 grayscale image. The define_generator() function below implements this and returns the defined generator model.
# define the standalone generator model def define_generator(latent_dim): # image generator input in_lat = Input(shape=(latent_dim,)) # foundation for 7x7 image n_nodes = 128 * 7 * 7 gen = Dense(n_nodes)(in_lat) gen = LeakyReLU(alpha=0.2)(gen) gen = Reshape((7, 7, 128))(gen) # upsample to 14x14 gen = Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')(gen) gen = LeakyReLU(alpha=0.2)(gen) # upsample to 28x28 gen = Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')(gen) gen = LeakyReLU(alpha=0.2)(gen) # output out_layer = Conv2D(1, (7,7), activation='tanh', padding='same')(gen) # define model model = Model(in_lat, out_layer) return model
The generator model will be fit via the unsupervised discriminator model.
We will use the composite model architecture, common to training the generator model when implemented in Keras. Specifically, weight sharing is used where the output of the generator model is passed directly to the unsupervised discriminator model, and the weights of the discriminator are marked as not trainable.
The define_gan() function below implements this, taking the already-defined generator and discriminator models as input and returning the composite model used to train the weights of the generator model.
# define the combined generator and discriminator model, for updating the generator def define_gan(g_model, d_model): # make weights in the discriminator not trainable d_model.trainable = False # connect image output from generator as input to discriminator gan_output = d_model(g_model.output) # define gan model as taking noise and outputting a classification model = Model(g_model.input, gan_output) # compile model opt = Adam(lr=0.0002, beta_1=0.5) model.compile(loss='binary_crossentropy', optimizer=opt) return model
We can load the training dataset and scale the pixels to the range [-1, 1] to match the output values of the generator model.
# load the images
def load_real_samples():
# load dataset
(trainX, trainy), (_, _) = load_data()
# expand to 3d, e.g. add channels
X = expand_dims(trainX, axis=-1)
# convert from ints to floats
X = X.astype('float32')
# scale from [0,255] to [-1,1]
X = (X - 127.5) / 127.5
print(X.shape, trainy.shape)
return [X, trainy]
We can also define a function to select a subset of the training dataset in which we keep the labels and train the supervised version of the discriminator model.
The select_supervised_samples() function below implements this and is careful to ensure that the selection of examples is random and that the classes are balanced. The number of labeled examples is parameterized and set at 100, meaning that each of the 10 classes will have 10 randomly selected examples.
# select a supervised subset of the dataset, ensures classes are balanced def select_supervised_samples(dataset, n_samples=100, n_classes=10): X, y = dataset X_list, y_list = list(), list() n_per_class = int(n_samples / n_classes) for i in range(n_classes): # get all images for this class X_with_class = X[y == i] # choose random instances ix = randint(0, len(X_with_class), n_per_class) # add to list [X_list.append(X_with_class[j]) for j in ix] [y_list.append(i) for j in ix] return asarray(X_list), asarray(y_list)
Next, we can define a function for retrieving a batch of real training examples.
A sample of images and labels is selected, with replacement. This same function can be used to retrieve examples from the labeled and unlabeled dataset, later when we train the models. In the case of the “unlabeled dataset“, we will ignore the labels.
# select real samples def generate_real_samples(dataset, n_samples): # split into images and labels images, labels = dataset # choose random instances ix = randint(0, images.shape[0], n_samples) # select images and labels X, labels = images[ix], labels[ix] # generate class labels y = ones((n_samples, 1)) return [X, labels], y
Next, we can define functions to help in generating images using the generator model.
First, the generate_latent_points() function will create a batch worth of random points in the latent space that can be used as input for generating images. The generate_fake_samples() function will call this function to generate a batch worth of images that can be fed to the unsupervised discriminator model or the composite GAN model during training.
# generate points in latent space as input for the generator def generate_latent_points(latent_dim, n_samples): # generate points in the latent space z_input = randn(latent_dim * n_samples) # reshape into a batch of inputs for the network z_input = z_input.reshape(n_samples, latent_dim) return z_input # use the generator to generate n fake examples, with class labels def generate_fake_samples(generator, latent_dim, n_samples): # generate points in latent space z_input = generate_latent_points(latent_dim, n_samples) # predict outputs images = generator.predict(z_input) # create class labels y = zeros((n_samples, 1)) return images, y
Next, we can define a function to be called when we want to evaluate the performance of the model.
This function will generate and plot 100 images using the current state of the generator model. This plot of images can be used to subjectively evaluate the performance of the generator model.
The supervised discriminator model is then evaluated on the entire training dataset, and the classification accuracy is reported. Finally, the generator model and the supervised discriminator model are saved to file, to be used later.
The summarize_performance() function below implements this and can be called periodically, such as the end of every training epoch. The results can be reviewed at the end of the run to select a classifier and even generator models.
# generate samples and save as a plot and save the model
def summarize_performance(step, g_model, c_model, latent_dim, dataset, n_samples=100):
# prepare fake examples
X, _ = generate_fake_samples(g_model, latent_dim, n_samples)
# scale from [-1,1] to [0,1]
X = (X + 1) / 2.0
# plot images
for i in range(100):
# define subplot
pyplot.subplot(10, 10, 1 + i)
# turn off axis
pyplot.axis('off')
# plot raw pixel data
pyplot.imshow(X[i, :, :, 0], cmap='gray_r')
# save plot to file
filename1 = 'generated_plot_%04d.png' % (step+1)
pyplot.savefig(filename1)
pyplot.close()
# evaluate the classifier model
X, y = dataset
_, acc = c_model.evaluate(X, y, verbose=0)
print('Classifier Accuracy: %.3f%%' % (acc * 100))
# save the generator model
filename2 = 'g_model_%04d.h5' % (step+1)
g_model.save(filename2)
# save the classifier model
filename3 = 'c_model_%04d.h5' % (step+1)
c_model.save(filename3)
print('>Saved: %s, %s, and %s' % (filename1, filename2, filename3))
Next, we can define a function to train the models. The defined models and loaded training dataset are provided as arguments, and the number of training epochs and batch size are parameterized with default values, in this case 20 epochs and a batch size of 100.
The chosen model configuration was found to overfit the training dataset quickly, hence the relatively smaller number of training epochs. Increasing the epochs to 100 or more results in much higher-quality generated images, but a lower-quality classifier model. Balancing these two concerns might make a fun extension.
First, the labeled subset of the training dataset is selected, and the number of training steps is calculated.
The training process is almost identical to the training of a vanilla GAN model, with the addition of updating the supervised model with labeled examples.
A single cycle through updating the models involves first updating the supervised discriminator model with labeled examples, then updating the unsupervised discriminator model with unlabeled real and generated examples. Finally, the generator model is updated via the composite model.
The shared weights of the discriminator model get updated with 1.5 batches worth of samples, whereas the weights of the generator model are updated with one batch worth of samples each iteration. Changing this so that each model is updated by the same amount might improve the model training process.
# train the generator and discriminator
def train(g_model, d_model, c_model, gan_model, dataset, latent_dim, n_epochs=20, n_batch=100):
# select supervised dataset
X_sup, y_sup = select_supervised_samples(dataset)
print(X_sup.shape, y_sup.shape)
# calculate the number of batches per training epoch
bat_per_epo = int(dataset[0].shape[0] / n_batch)
# calculate the number of training iterations
n_steps = bat_per_epo * n_epochs
# calculate the size of half a batch of samples
half_batch = int(n_batch / 2)
print('n_epochs=%d, n_batch=%d, 1/2=%d, b/e=%d, steps=%d' % (n_epochs, n_batch, half_batch, bat_per_epo, n_steps))
# manually enumerate epochs
for i in range(n_steps):
# update supervised discriminator (c)
[Xsup_real, ysup_real], _ = generate_real_samples([X_sup, y_sup], half_batch)
c_loss, c_acc = c_model.train_on_batch(Xsup_real, ysup_real)
# update unsupervised discriminator (d)
[X_real, _], y_real = generate_real_samples(dataset, half_batch)
d_loss1 = d_model.train_on_batch(X_real, y_real)
X_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch)
d_loss2 = d_model.train_on_batch(X_fake, y_fake)
# update generator (g)
X_gan, y_gan = generate_latent_points(latent_dim, n_batch), ones((n_batch, 1))
g_loss = gan_model.train_on_batch(X_gan, y_gan)
# summarize loss on this batch
print('>%d, c[%.3f,%.0f], d[%.3f,%.3f], g[%.3f]' % (i+1, c_loss, c_acc*100, d_loss1, d_loss2, g_loss))
# evaluate the model performance every so often
if (i+1) % (bat_per_epo * 1) == 0:
summarize_performance(i, g_model, c_model, latent_dim, dataset)
Finally, we can define the models and call the function to train and save the models.
# size of the latent space latent_dim = 100 # create the discriminator models d_model, c_model = define_discriminator() # create the generator g_model = define_generator(latent_dim) # create the gan gan_model = define_gan(g_model, d_model) # load image data dataset = load_real_samples() # train model train(g_model, d_model, c_model, gan_model, dataset, latent_dim)
Tying all of this together, the complete example of training a semi-supervised GAN on the MNIST handwritten digit image classification task is listed below.
# example of semi-supervised gan for mnist
from numpy import expand_dims
from numpy import zeros
from numpy import ones
from numpy import asarray
from numpy.random import randn
from numpy.random import randint
from keras.datasets.mnist import load_data
from keras.optimizers import Adam
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers import Reshape
from keras.layers import Flatten
from keras.layers import Conv2D
from keras.layers import Conv2DTranspose
from keras.layers import LeakyReLU
from keras.layers import Dropout
from keras.layers import Lambda
from keras.layers import Activation
from matplotlib import pyplot
from keras import backend
# custom activation function
def custom_activation(output):
logexpsum = backend.sum(backend.exp(output), axis=-1, keepdims=True)
result = logexpsum / (logexpsum + 1.0)
return result
# define the standalone supervised and unsupervised discriminator models
def define_discriminator(in_shape=(28,28,1), n_classes=10):
# image input
in_image = Input(shape=in_shape)
# downsample
fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(in_image)
fe = LeakyReLU(alpha=0.2)(fe)
# downsample
fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe)
fe = LeakyReLU(alpha=0.2)(fe)
# downsample
fe = Conv2D(128, (3,3), strides=(2,2), padding='same')(fe)
fe = LeakyReLU(alpha=0.2)(fe)
# flatten feature maps
fe = Flatten()(fe)
# dropout
fe = Dropout(0.4)(fe)
# output layer nodes
fe = Dense(n_classes)(fe)
# supervised output
c_out_layer = Activation('softmax')(fe)
# define and compile supervised discriminator model
c_model = Model(in_image, c_out_layer)
c_model.compile(loss='sparse_categorical_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5), metrics=['accuracy'])
# unsupervised output
d_out_layer = Lambda(custom_activation)(fe)
# define and compile unsupervised discriminator model
d_model = Model(in_image, d_out_layer)
d_model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5))
return d_model, c_model
# define the standalone generator model
def define_generator(latent_dim):
# image generator input
in_lat = Input(shape=(latent_dim,))
# foundation for 7x7 image
n_nodes = 128 * 7 * 7
gen = Dense(n_nodes)(in_lat)
gen = LeakyReLU(alpha=0.2)(gen)
gen = Reshape((7, 7, 128))(gen)
# upsample to 14x14
gen = Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')(gen)
gen = LeakyReLU(alpha=0.2)(gen)
# upsample to 28x28
gen = Conv2DTranspose(128, (4,4), strides=(2,2), padding='same')(gen)
gen = LeakyReLU(alpha=0.2)(gen)
# output
out_layer = Conv2D(1, (7,7), activation='tanh', padding='same')(gen)
# define model
model = Model(in_lat, out_layer)
return model
# define the combined generator and discriminator model, for updating the generator
def define_gan(g_model, d_model):
# make weights in the discriminator not trainable
d_model.trainable = False
# connect image output from generator as input to discriminator
gan_output = d_model(g_model.output)
# define gan model as taking noise and outputting a classification
model = Model(g_model.input, gan_output)
# compile model
opt = Adam(lr=0.0002, beta_1=0.5)
model.compile(loss='binary_crossentropy', optimizer=opt)
return model
# load the images
def load_real_samples():
# load dataset
(trainX, trainy), (_, _) = load_data()
# expand to 3d, e.g. add channels
X = expand_dims(trainX, axis=-1)
# convert from ints to floats
X = X.astype('float32')
# scale from [0,255] to [-1,1]
X = (X - 127.5) / 127.5
print(X.shape, trainy.shape)
return [X, trainy]
# select a supervised subset of the dataset, ensures classes are balanced
def select_supervised_samples(dataset, n_samples=100, n_classes=10):
X, y = dataset
X_list, y_list = list(), list()
n_per_class = int(n_samples / n_classes)
for i in range(n_classes):
# get all images for this class
X_with_class = X[y == i]
# choose random instances
ix = randint(0, len(X_with_class), n_per_class)
# add to list
[X_list.append(X_with_class[j]) for j in ix]
[y_list.append(i) for j in ix]
return asarray(X_list), asarray(y_list)
# select real samples
def generate_real_samples(dataset, n_samples):
# split into images and labels
images, labels = dataset
# choose random instances
ix = randint(0, images.shape[0], n_samples)
# select images and labels
X, labels = images[ix], labels[ix]
# generate class labels
y = ones((n_samples, 1))
return [X, labels], y
# generate points in latent space as input for the generator
def generate_latent_points(latent_dim, n_samples):
# generate points in the latent space
z_input = randn(latent_dim * n_samples)
# reshape into a batch of inputs for the network
z_input = z_input.reshape(n_samples, latent_dim)
return z_input
# use the generator to generate n fake examples, with class labels
def generate_fake_samples(generator, latent_dim, n_samples):
# generate points in latent space
z_input = generate_latent_points(latent_dim, n_samples)
# predict outputs
images = generator.predict(z_input)
# create class labels
y = zeros((n_samples, 1))
return images, y
# generate samples and save as a plot and save the model
def summarize_performance(step, g_model, c_model, latent_dim, dataset, n_samples=100):
# prepare fake examples
X, _ = generate_fake_samples(g_model, latent_dim, n_samples)
# scale from [-1,1] to [0,1]
X = (X + 1) / 2.0
# plot images
for i in range(100):
# define subplot
pyplot.subplot(10, 10, 1 + i)
# turn off axis
pyplot.axis('off')
# plot raw pixel data
pyplot.imshow(X[i, :, :, 0], cmap='gray_r')
# save plot to file
filename1 = 'generated_plot_%04d.png' % (step+1)
pyplot.savefig(filename1)
pyplot.close()
# evaluate the classifier model
X, y = dataset
_, acc = c_model.evaluate(X, y, verbose=0)
print('Classifier Accuracy: %.3f%%' % (acc * 100))
# save the generator model
filename2 = 'g_model_%04d.h5' % (step+1)
g_model.save(filename2)
# save the classifier model
filename3 = 'c_model_%04d.h5' % (step+1)
c_model.save(filename3)
print('>Saved: %s, %s, and %s' % (filename1, filename2, filename3))
# train the generator and discriminator
def train(g_model, d_model, c_model, gan_model, dataset, latent_dim, n_epochs=20, n_batch=100):
# select supervised dataset
X_sup, y_sup = select_supervised_samples(dataset)
print(X_sup.shape, y_sup.shape)
# calculate the number of batches per training epoch
bat_per_epo = int(dataset[0].shape[0] / n_batch)
# calculate the number of training iterations
n_steps = bat_per_epo * n_epochs
# calculate the size of half a batch of samples
half_batch = int(n_batch / 2)
print('n_epochs=%d, n_batch=%d, 1/2=%d, b/e=%d, steps=%d' % (n_epochs, n_batch, half_batch, bat_per_epo, n_steps))
# manually enumerate epochs
for i in range(n_steps):
# update supervised discriminator (c)
[Xsup_real, ysup_real], _ = generate_real_samples([X_sup, y_sup], half_batch)
c_loss, c_acc = c_model.train_on_batch(Xsup_real, ysup_real)
# update unsupervised discriminator (d)
[X_real, _], y_real = generate_real_samples(dataset, half_batch)
d_loss1 = d_model.train_on_batch(X_real, y_real)
X_fake, y_fake = generate_fake_samples(g_model, latent_dim, half_batch)
d_loss2 = d_model.train_on_batch(X_fake, y_fake)
# update generator (g)
X_gan, y_gan = generate_latent_points(latent_dim, n_batch), ones((n_batch, 1))
g_loss = gan_model.train_on_batch(X_gan, y_gan)
# summarize loss on this batch
print('>%d, c[%.3f,%.0f], d[%.3f,%.3f], g[%.3f]' % (i+1, c_loss, c_acc*100, d_loss1, d_loss2, g_loss))
# evaluate the model performance every so often
if (i+1) % (bat_per_epo * 1) == 0:
summarize_performance(i, g_model, c_model, latent_dim, dataset)
# size of the latent space
latent_dim = 100
# create the discriminator models
d_model, c_model = define_discriminator()
# create the generator
g_model = define_generator(latent_dim)
# create the gan
gan_model = define_gan(g_model, d_model)
# load image data
dataset = load_real_samples()
# train model
train(g_model, d_model, c_model, gan_model, dataset, latent_dim)
The example can be run on a workstation with a CPU or GPU hardware, although a GPU is recommended for faster execution.
Given the stochastic nature of the training algorithm, your specific results will vary. Consider running the example a few times.
At the start of the run, the size of the training dataset is summarized, as is the supervised subset, confirming our configuration.
The performance of each model is summarized at the end of each update, including the loss and accuracy of the supervised discriminator model (c), the loss of the unsupervised discriminator model on real and generated examples (d), and the loss of the generator model updated via the composite model (g).
The loss for the supervised model will shrink to a small value close to zero and accuracy will hit 100%, which will be maintained for the entire run. The loss of the unsupervised discriminator and generator should remain at modest values throughout the run if they are kept in equilibrium.
(60000, 28, 28, 1) (60000,) (100, 28, 28, 1) (100,) n_epochs=20, n_batch=100, 1/2=50, b/e=600, steps=12000 >1, c[2.305,6], d[0.096,2.399], g[0.095] >2, c[2.298,18], d[0.089,2.399], g[0.095] >3, c[2.308,10], d[0.084,2.401], g[0.095] >4, c[2.304,8], d[0.080,2.404], g[0.095] >5, c[2.254,18], d[0.077,2.407], g[0.095] ...
The supervised classification model is evaluated on the entire training dataset at the end of every training epoch, in this case after every 600 training updates. At this time, the performance of the model is summarized, showing that it rapidly achieves good skill.
This is surprising given that the model is only trained on 10 labeled examples of each class.
Classifier Accuracy: 85.543% Classifier Accuracy: 91.487% Classifier Accuracy: 92.628% Classifier Accuracy: 94.017% Classifier Accuracy: 94.252% Classifier Accuracy: 93.828% Classifier Accuracy: 94.122% Classifier Accuracy: 93.597% Classifier Accuracy: 95.283% Classifier Accuracy: 95.287% Classifier Accuracy: 95.263% Classifier Accuracy: 95.432% Classifier Accuracy: 95.270% Classifier Accuracy: 95.212% Classifier Accuracy: 94.803% Classifier Accuracy: 94.640% Classifier Accuracy: 93.622% Classifier Accuracy: 91.870% Classifier Accuracy: 92.525% Classifier Accuracy: 92.180%
The models are also saved at the end of each training epoch and plots of generated images are also created.
The quality of the generated images is good given the relatively small number of training epochs.
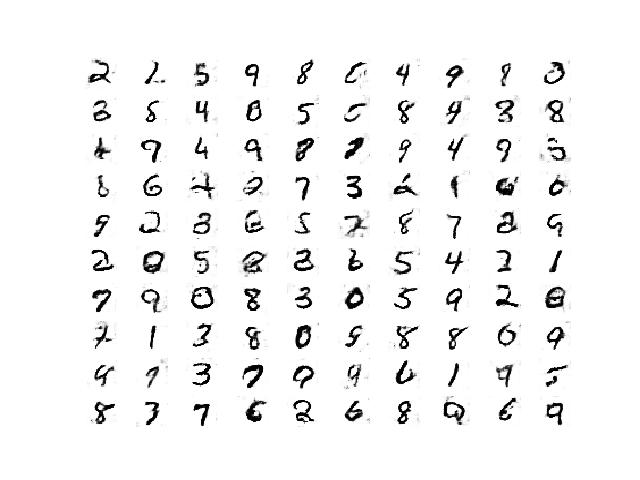
Plot of Handwritten Digits Generated by the Semi-Supervised GAN After 8400 Updates.
How to Load and Use the Final SGAN Classifier Model
Now that we have trained the generator and discriminator models, we can make use of them.
In the case of the semi-supervised GAN, we are less interested in the generator model and more interested in the supervised model.
Reviewing the results for the specific run, we can select a specific saved model that is known to have good performance on the test dataset. In this case, the model saved after 12 training epochs, or 7,200 updates, that had a classification accuracy of about 95.432% on the training dataset.
We can load the model directly via the load_model() Keras function.
...
# load the model
model = load_model('c_model_7200.h5')
Once loaded, we can evaluate it on the entire training dataset again to confirm the finding, then evaluate it on the holdout test dataset.
Recall, the feature extraction layers expect the input images to have the pixel values scaled to the range [-1,1], therefore, this must be performed before any images are provided to the model.
The complete example of loading the saved semi-supervised classifier model and evaluating it in the complete MNIST dataset is listed below.
# example of loading the classifier model and generating images
from numpy import expand_dims
from keras.models import load_model
from keras.datasets.mnist import load_data
# load the model
model = load_model('c_model_7200.h5')
# load the dataset
(trainX, trainy), (testX, testy) = load_data()
# expand to 3d, e.g. add channels
trainX = expand_dims(trainX, axis=-1)
testX = expand_dims(testX, axis=-1)
# convert from ints to floats
trainX = trainX.astype('float32')
testX = testX.astype('float32')
# scale from [0,255] to [-1,1]
trainX = (trainX - 127.5) / 127.5
testX = (testX - 127.5) / 127.5
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
print('Train Accuracy: %.3f%%' % (train_acc * 100))
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Test Accuracy: %.3f%%' % (test_acc * 100))
Running the example loads the model and evaluates it on the MNIST dataset.
We can see that, in this case, the model achieves the expected performance of 95.432% on the training dataset, confirming we have loaded the correct model.
We can also see that the accuracy on the holdout test dataset is as good, or slightly better, at about 95.920%. This shows that the learned classifier has good generalization.
Train Accuracy: 95.432% Test Accuracy: 95.920%
We have successfully demonstrated the training and evaluation of a semi-supervised classifier model fit via the GAN architecture.
Extensions
This section lists some ideas for extending the tutorial that you may wish to explore.
- Standalone Classifier. Fit a standalone classifier model on the labeled dataset directly and compare performance to the SGAN model.
- Number of Labeled Examples. Repeat the example of more or fewer labeled examples and compare the performance of the model
- Model Tuning. Tune the performance of the discriminator and generator model to further lift the performance of the supervised model closer toward state-of-the-art results.
If you explore any of these extensions, I’d love to know.
Post your findings in the comments below.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Papers
- Semi-Supervised Learning with Generative Adversarial Networks, 2016.
- Improved Techniques for Training GANs, 2016.
- Unsupervised and Semi-supervised Learning with Categorical Generative Adversarial Networks, 2015.
- Semi-supervised Learning with GANs: Manifold Invariance with Improved Inference, 2017.
- Semi-Supervised Learning with GANs: Revisiting Manifold Regularization, 2018.
API
- Keras Datasets API.
- Keras Sequential Model API
- Keras Convolutional Layers API
- How can I “freeze” Keras layers?
- MatplotLib API
- NumPy Random sampling (numpy.random) API
- NumPy Array manipulation routines
Articles
- Semi-supervised learning with GANs, 2018.
- Semi-supervised learning with Generative Adversarial Networks (GANs), 2017.
Projects
- Improved GAN Project (Official), GitHub.
- Keras GAN Project, GitHub.
- GAN for semi-supervised learning Project, GitHub
Summary
In this tutorial, you discovered how to develop a Semi-Supervised Generative Adversarial Network from scratch.
Specifically, you learned:
- The semi-supervised GAN is an extension of the GAN architecture for training a classifier model while making use of labeled and unlabeled data.
- There are at least three approaches to implementing the supervised and unsupervised discriminator models in Keras used in the semi-supervised GAN.
- How to train a semi-supervised GAN from scratch on MNIST and load and use the trained classifier for making predictions.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post How to Implement a Semi-Supervised GAN (SGAN) From Scratch in Keras appeared first on Machine Learning Mastery.