
Author: datascience@berkeley Staff

An estimated 5.9 million surveillance cameras keep watch over the United Kingdom. While this may sound intimidating to those unaware they are being surveilled, this network of closed-circuit TV cameras helped British authorities piece together the mysterious poisoning of Sergei Skripal, a former Russian intelligence officer turned double agent, and his daughter, Yulia. Super recognizers, people hired for their above-average ability to recognize faces, sorted through thousands of hours of video footage and eventually homed in on two particular suspects. The pair had flown into London’s Gatwick Airport and then traveled to Salisbury, where they carried out the attack. Through the investigation, the British police identified and charged the men, Russian intelligence officers, with attempted murder.
Having a goal, an explicit purpose in collecting and analyzing a dataset, is how scientists can harness the power of data to solve problems and answer questions.
The public would call this big data in action: a mass of video footage combed by specially trained police analysts to solve an international crime. The case is a story of heroes and villains, of cracking a case with an attention to detail worthy of Sherlock Holmes. But when we reduce our language to the catch-all term big data, we lose the story. We run the risk of forgetting why we collect data in the first place: to make our world better through granular details, like an oil painter with a palette knife.
Knowing the story makes data valuable. Having a goal, an explicit purpose in collecting and analyzing a dataset, is how scientists can harness the power of data to solve problems and answer questions, ranging from the query of who poisoned the Skripals to the lighthearted question of why contemporary summer songs tend to sound similar.
The way we talk about data matters, because it shapes the way we think about data. And the ways we apply, fund, and support data today will shape the future of our society.
Modern data analytics allows scientists to answer complex questions using highly specific techniques. However, the public continues to use the generalized term big data and all of its iterations — big data technology, big data analytics, and big data tools — to describe their methods.
The way we talk about data matters, because it shapes the way we think about data. And the ways we apply, fund, and support data today will shape the future of our society, according to AnnaLee Saxenian, dean of the UC Berkeley School of Information (I School).
So, why do we still hear the term “big data”? Dean Saxenian offers her insights on where the term came from and which words we should use instead.
What Is Big Data?
At the beginning of the information age, big data seemed to aptly describe the technological, cultural, and economic shifts of the early 2000s.
“We started to have access to a whole bunch of new forms of data: data from the web, data from mobile devices, and, more recently, data from sensor networks,” said Dean Saxenian. Previously, much of the data that scholars used was based on surveys and other kinds of administrative information. The numbers were neatly organized into predetermined categories: for example, the number of employees who rate their job experiences as satisfactory, or the number of college graduates who earn more than $50,000 per year.
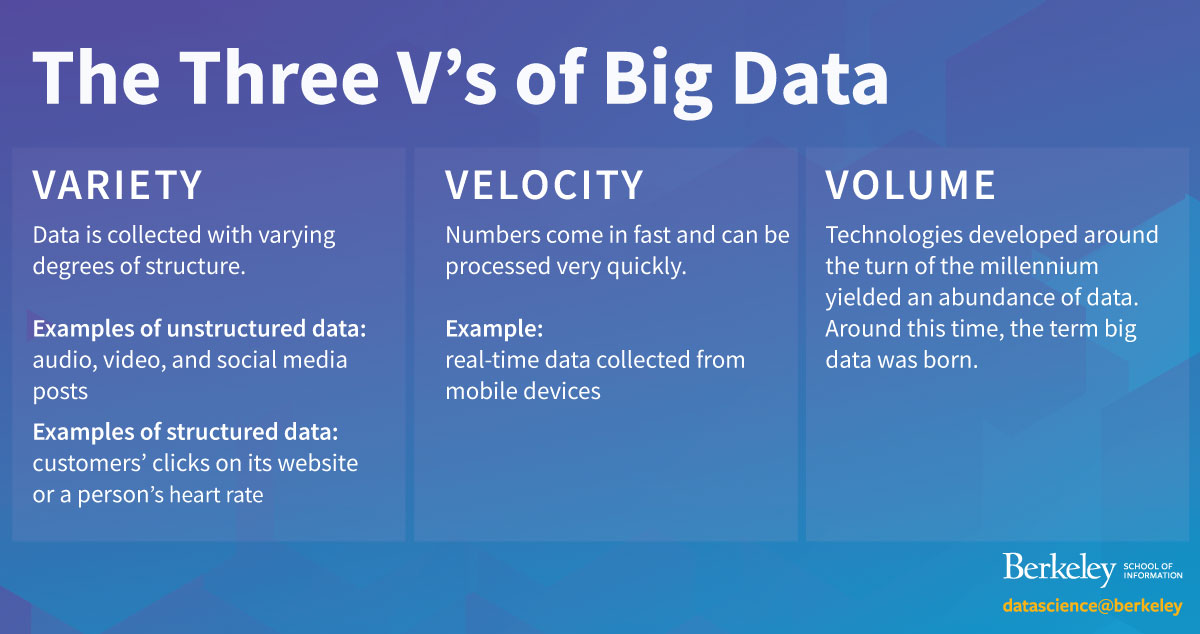
But this new digital data was different and demonstrated what theorists call the three V’s: variety, velocity, and volume.
“I think [the big data concept] became popular because it did capture the fact that we felt like we were all of a sudden flooded with data.”
— AnnaLee Saxenian, dean of the UC Berkeley School of Information (I School)
Digitally sourced data has variety in that they are collected with varying degrees of structure. Data can be heavily unstructured; audio, video, and social media posts can be considered unstructured data. A company can gather more structured data on customers’ clicks on its website, or a person can track her heart rate and physical activity with a wearable device, but data must then be organized in order to be useful. Multi-structured data can involve combinations of structured and unstructured data, organized by similar attributes.
This new kind of data has velocity, meaning the numbers come in fast and can be processed very quickly. Today, a company can real-time process data collected from mobile devices using analytics and data mining tools.
Most compellingly, this data has volume. The latest technologies developed around the turn of the millennium yielded what Dean Saxenian calls “a firehose of data.” Around this time, the term big data was born.
“I think [the big data concept] became popular because it did capture the fact that we felt like we were all of a sudden flooded with data,” Dean Saxenian said. The magnitude of this moment is difficult to overstate. As a graduate student before the dawning of the digital age, Dean Saxenian had to go to the library at UC Berkeley to make photocopies of government census data from hard copy volumes. With millennium-era technology, anyone can access this same data in seconds — and not just from one census, but from all of them. “Nobody [at the time] knew how to deal with it,” Saxenian said.
Today, the concept of big data is not only less compelling, but it’s also potentially misleading.
But in the past two decades, big data has been cut down to size. Data scientists have created new tools for collecting, storing, and analyzing these vast amounts of information. “In some sense, the ‘big’ part has become less compelling,” Saxenian said.
Moving Away from Big Data
Today, the concept of big data is not only less compelling, but it’s also potentially misleading. Size is only one of many important aspects of a data set. The term big data hints at a misconception that high volume means good data and strong insights.
“We want students and consumers of our research to understand that volume isn’t sufficient to getting good answers,” Saxenian said.
The story we tell about the data — the questions we ask about the numbers and the way we organize them — matters as much as, if not more than, the size of the set. Professionals working with data should focus on cleaning the data well, classifying it correctly, and understanding the causal story.
By thinking systematically about data, from our language to our methods, we can better position ourselves to use data science for the good of our communities.
The UC Berkeley I School challenges students in the online Master of Information and Data Science program to approach data with intentionality, beginning with the way they talk about data. They learn to dig deeper by asking basic questions: Where does the data come from? How was it collected and was the process ethical? What kinds of questions can this data set answer, and which can it not?
This process is part of data science. A more useful shorthand than big data, the words imply the rigorous approach to analytics and data mining that Dean Saxenian supports.
“Data science, like social and other sciences, is not just about using the tools,” she said. “It’s also using the tools in a way that allows you to solve problems and make sense of data in a systematic way.” Ultimately, a data set is not so much a painting to be admired but a window to be utilized; scientists use data to see the world and our society’s problems more clearly.
By thinking systematically about data, from our language to our methods, we can better position ourselves to use data science for the good of our communities. “Approaching it more intentionally,” Dean Saxenian concluded, “will give us the best shot at being good stewards for future generations of the technology.”
Citation for this content: datascience@berkeley, the online Master of Information and Data Science from UC Berkeley