
Author: Jason Brownlee
Progressive Growing GAN is an extension to the GAN training process that allows for the stable training of generator models that can output large high-quality images.
It involves starting with a very small image and incrementally adding blocks of layers that increase the output size of the generator model and the input size of the discriminator model until the desired image size is achieved.
This approach has proven effective at generating high-quality synthetic faces that are startlingly realistic.
In this post, you will discover the progressive growing generative adversarial network for generating large images.
After reading this post, you will know:
- GANs are effective at generating sharp images, although they are limited to small image sizes because of model stability.
- Progressive growing GAN is a stable approach to training GAN models to generate large high-quality images that involves incrementally increasing the size of the model during training.
- Progressive growing GAN models are capable of generating photorealistic synthetic faces and objects at high resolution that are remarkably realistic.
Discover how to develop DCGANs, conditional GANs, Pix2Pix, CycleGANs, and more with Keras in my new GANs book, with 29 step-by-step tutorials and full source code.
Let’s get started.

A Gentle Introduction to Progressive Growing Generative Adversarial Networks
Photo by Sandrine Néel, some rights reserved.
Overview
This tutorial is divided into five parts; they are:
- GANs Are Generally Limited to Small Images
- Generate Large Images by Progressively Adding Layers
- How to Progressively Grow a GAN
- Images Generated by the Progressive Growing GAN
- How to Configure Progressive Growing GAN Models
GANs Are Generally Limited to Small Images
Generative Adversarial Networks, or GANs for short, are an effective approach for training deep convolutional neural network models for generating synthetic images.
Training a GAN model involves two models: a generator used to output synthetic images, and a discriminator model used to classify images as real or fake, which is used to train the generator model. The two models are trained together in an adversarial manner, seeking an equilibrium.
Compared to other approaches, they are both fast and result in crisp images.
A problem with GANs is that they are limited to small dataset sizes, often a few hundred pixels and often less than 100-pixel square images.
GANs produce sharp images, albeit only in fairly small resolutions and with somewhat limited variation, and the training continues to be unstable despite recent progress.
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
Generating high-resolution images is believed to be challenging for GAN models as the generator must learn how to output both large structure and fine details at the same time.
The high resolution makes any issues in the fine detail of generated images easy to spot for the discriminator and the training process fails.
The generation of high-resolution images is difficult because higher resolution makes it easier to tell the generated images apart from training images …
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
Large images, such as 1024-pixel square images, also require significantly more memory, which is in relatively limited supply on modern GPU hardware compared to main memory.
As such, the batch size that defines the number of images used to update model weights each training iteration must be reduced to ensure that the large images fit into memory. This, in turn, introduces further instability into the training process.
Large resolutions also necessitate using smaller minibatches due to memory constraints, further compromising training stability.
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
Additionally, the training of GAN models remains unstable, even in the presence of a suite of empirical techniques designed to improve the stability of the model training process.
Want to Develop GANs from Scratch?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Generate Large Images by Progressively Adding Layers
A solution to the problem of training stable GAN models for larger images is to progressively increase the number of layers during the training process.
This approach is called Progressive Growing GAN, Progressive GAN, or PGGAN for short.
The approach was proposed by Tero Karras, et al. from Nvidia in the 2017 paper titled “Progressive Growing of GANs for Improved Quality, Stability, and Variation” and presented at the 2018 ICLR conference.
Our primary contribution is a training methodology for GANs where we start with low-resolution images, and then progressively increase the resolution by adding layers to the networks.
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
Progressive Growing GAN involves using a generator and discriminator model with the same general structure and starting with very small images, such as 4×4 pixels.
During training, new blocks of convolutional layers are systematically added to both the generator model and the discriminator models.
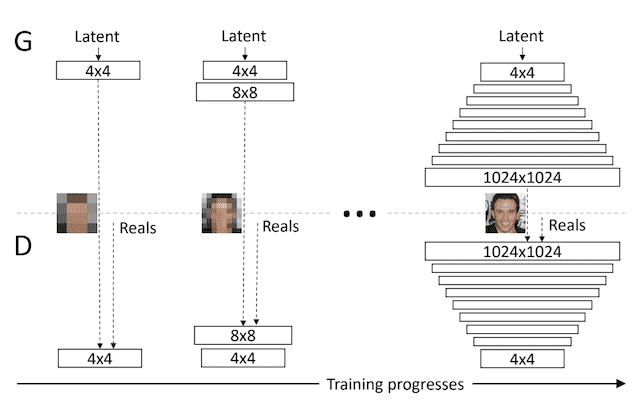
Example of Progressively Adding Layers to Generator and Discriminator Models.
Taken from: Progressive Growing of GANs for Improved Quality, Stability, and Variation.
The incremental addition of the layers allows the models to effectively learn coarse-level detail and later learn ever finer detail, both on the generator and discriminator side.
This incremental nature allows the training to first discover large-scale structure of the image distribution and then shift attention to increasingly finer scale detail, instead of having to learn all scales simultaneously.
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
This approach allows the generation of large high-quality images, such as 1024×1024 photorealistic faces of celebrities that do not exist.
How to Progressively Grow a GAN
Progressive Growing GAN requires that the capacity of both the generator and discriminator model be expanded by adding layers during the training process.
This is much like the greedy layer-wise training process that was common for developing deep learning neural networks prior to the development of ReLU and Batch Normalization.
For example, see the post:
Unlike greedy layer-wise pretraining, progressive growing GAN involves adding blocks of layers and phasing in the addition of the blocks of layers rather than adding them directly.
When new layers are added to the networks, we fade them in smoothly […] This avoids sudden shocks to the already well-trained, smaller-resolution layers.
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
Further, all layers remain trainable during the training process, including existing layers when new layers are added.
All existing layers in both networks remain trainable throughout the training process.
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
The phasing in of a new block of layers involves using a skip connection to connect the new block to the input of the discriminator or output of the generator and adding it to the existing input or output layer with a weighting. The weighting controls the influence of the new block and is achieved using a parameter alpha (a) that starts at zero or a very small number and linearly increases to 1.0 over training iterations.
This is demonstrated in the figure below, taken from the paper.
It shows a generator that outputs a 16×16 image and a discriminator that takes a 16×16 pixel image. The models are grown to the size of 32×32.
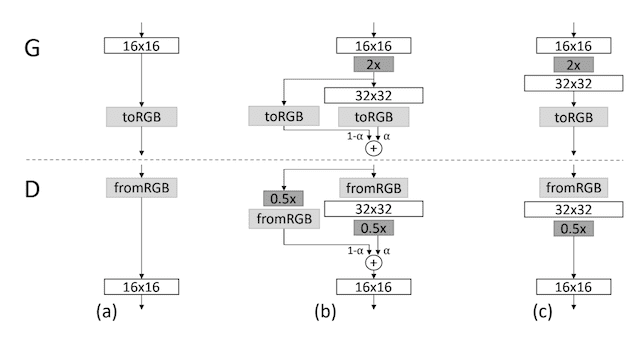
Example of Phasing in the Addition of New Layers to the Generator and Discriminator Models.
Taken from: Progressive Growing of GANs for Improved Quality, Stability, and Variation.
Let’s take a closer look at how to progressively add layers to the generator and discriminator when going from 16×16 to 32×32 pixels.
Growing the Generator
For the generator, this involves adding a new block of convolutional layers that outputs a 32×32 image.
The output of this new layer is combined with the output of the 16×16 layer that is upsampled using nearest neighbor interpolation to 32×32. This is different from many GAN generators that use a transpose convolutional layer.
… doubling […] the image resolution using nearest neighbor filtering
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
The contribution of the upsampled 16×16 layer is weighted by (1 – alpha), whereas the contribution of the new 32×32 layer is weighted by alpha.
Alpha is small initially, giving the most weight to the scaled-up version of the 16×16 image, although slowly transitions to giving more weight and then all weight to the new 32×32 output layers over training iterations.
During the transition we treat the layers that operate on the higher resolution like a residual block, whose weight alpha increases linearly from 0 to 1.
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
Growing the Discriminator
For the discriminator, this involves adding a new block of convolutional layers for the input of the model to support image sizes with 32×32 pixels.
The input image is downsampled to 16×16 using average pooling so that it can pass through the existing 16×16 convolutional layers. The output of the new 32×32 block of layers is also downsampled using average pooling so that it can be provided as input to the existing 16×16 block. This is different from most GAN models that use a 2×2 stride in the convolutional layers to downsample.
… halving the image resolution using […] average pooling
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
The two downsampled versions of the input are combined in a weighted manner, starting with a full weighting to the downsampled raw input and linearly transitioning to a full weighting for the interpreted output of the new input layer block.
Images Generated by the Progressive Growing GAN
In this section, we can review some of the impressive results achieved with the Progressive Growing GAN described in the paper.
Many example images are provided in the appendix of the paper and I recommend reviewing it. Additionally, a YouTube video was also created summarizing the impressive results of the model.
Synthetic Photographs of Celebrity Faces
Perhaps the most impressive accomplishment of the Progressive Growing GAN is the generation of large 1024×1024 pixel photorealistic generated faces.
The model was trained on a high-quality version of the celebrity faces dataset, called CELEBA-HQ. As such, the faces look familiar as they contain elements of many real celebrity faces, although none of the people actually exist.

Example of Photorealistic Generated Faces Using Progressive Growing GAN.
Taken from: Progressive Growing of GANs for Improved Quality, Stability, and Variation.
Interestingly, the model required to generate the faces was trained on 8 GPUs for 4 days, perhaps out of the range of most developers.
We trained the network on 8 Tesla V100 GPUs for 4 days, after which we no longer observed qualitative differences between the results of consecutive training iterations. Our implementation used an adaptive minibatch size depending on the current output resolution so that the available memory budget was optimally utilized.
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
Synthetic Photographs of Objects
The model was also demonstrated on generating 256×256-pixel photorealistic synthetic objects from the LSUN dataset, such as bikes, buses, and churches.

Example of Photorealistic Generated Objects Using Progressive Growing GAN.
Taken from: Progressive Growing of GANs for Improved Quality, Stability, and Variation.
How to Configure Progressive Growing GAN Models
The paper describes the configuration details of the model used to generate the 1024×1024 synthetic photographs of celebrity faces.
Specifically, the details are provided in Appendix A.
Although we may not be interested or have the resources to develop such a large model, the configuration details may be useful when implementing a Progressive Growing GAN.
Both the discriminator and generator models were grown using blocks of convolutional layers, each using a specific number of filters with the size 3×3 and the LeakyReLU activation layer with the slope of 0.2. Upsampling was achieved via nearest neighbor sampling and downsampling was achieved using average pooling.
Both networks consist mainly of replicated 3-layer blocks that we introduce one by one during the course of the training. […] We use leaky ReLU with leakiness 0.2 in all layers of both networks, except for the last layer that uses linear activation.
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
The generator used a 512-element latent vector of Gaussian random variables. It also used an output layer with a 1×1-sized filters and a linear activation function, instead of the more common hyperbolic tangent activation function (tanh). The discriminator also used an output layer with 1×1-sized filters and a linear activation function.
The Wasserstein GAN loss was used with the gradient penalty, so-called WGAN-GP as described in the 2017 paper titled “Improved Training of Wasserstein GANs.” The least squares loss was tested and showed good results, but not as good as WGAN-GP.
The models start with a 4×4 input image and grow until they reach the 1024×1024 target.
Tables were provided that list the number of layers and number of filters used in each layer for the generator and discriminator models, reproduced below.
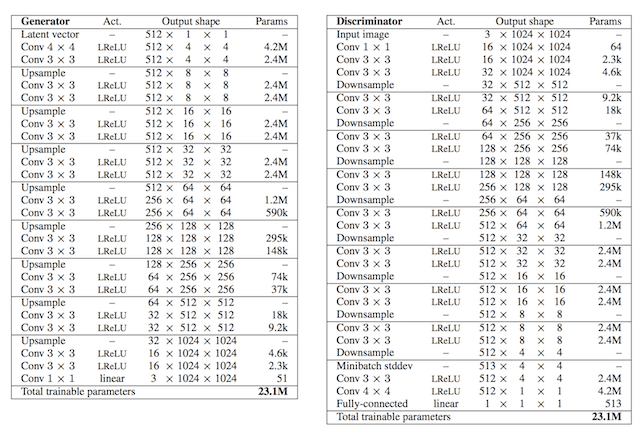
Tables Showing Generator and Discriminator Configuration for the Progressive Growing GAN.
Taken from: Progressive Growing of GANs for Improved Quality, Stability, and Variation.
Batch normalization is not used; instead, two other techniques are added, including minibatch standard deviation pixel-wise normalization.
The standard deviation of activations across images in the mini-batch is added as a new channel prior to the last block of convolutional layers in the discriminator model. This is referred to as “Minibatch standard deviation.”
We inject the across-minibatch standard deviation as an additional feature map at 4×4 resolution toward the end of the discriminator
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
A pixel-wise normalization is performed in the generator after each convolutional layer that normalizes each pixel value in the activation map across the channels to a unit length. This is a type of activation constraint that is more generally referred to as “local response normalization.”
The bias for all layers is initialized as zero and model weights are initialized as a random Gaussian rescaled using the He weight initialization method.
We initialize all bias parameters to zero and all weights according to the normal distribution with unit variance. However, we scale the weights with a layer-specific constant at runtime …
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
The models are optimized using the Adam version of stochastic gradient descent with a small learning rate and low momentum.
We train the networks using Adam with a = 0.001, B1=0, B2=0.99, and eta = 10^−8.
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
Image generation uses a weighted average of prior models rather a given model snapshot, much like a horizontal ensemble.
… visualizing generator output at any given point during the training, we use an exponential running average for the weights of the generator with decay 0.999
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
- Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
- Progressive Growing of GANs for Improved Quality, Stability, and Variation, Official.
- progressive_growing_of_gans Project (official), GitHub.
- Progressive Growing of GANs for Improved Quality, Stability, and Variation. Open Review.
- Progressive Growing of GANs for Improved Quality, Stability, and Variation, YouTube.
Summary
In this post, you discovered the progressive growing generative adversarial network for generating large images.
Specifically, you learned:
- GANs are effective at generating sharp images, although they are limited to small image sizes because of model stability.
- Progressive growing GAN is a stable approach to training GAN models to generate large high-quality images that involves incrementally increasing the size of the model during training.
- Progressive growing GAN models are capable of generating photorealistic synthetic faces and objects at high resolution that are remarkably realistic.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post A Gentle Introduction to the Progressive Growing GAN appeared first on Machine Learning Mastery.