
Author: Jason Brownlee
The No Free Lunch Theorem is often thrown around in the field of optimization and machine learning, often with little understanding of what it means or implies.
The theorem states that all optimization algorithms perform equally well when their performance is averaged across all possible problems.
It implies that there is no single best optimization algorithm. Because of the close relationship between optimization, search, and machine learning, it also implies that there is no single best machine learning algorithm for predictive modeling problems such as classification and regression.
In this tutorial, you will discover the no free lunch theorem for optimization and search.
After completing this tutorial, you will know:
- The no free lunch theorem suggests the performance of all optimization algorithms are identical, under some specific constraints.
- There is provably no single best optimization algorithm or machine learning algorithm.
- The practical implications of the theorem may be limited given we are interested in a small subset of all possible objective functions.
Let’s get started.

No Free Lunch Theorem for Machine Learning
Photo by Francisco Anzola, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
- What Is the No Free Lunch Theorem?
- Implications for Optimization
- Implications for Machine Learning
What Is the No Free Lunch Theorem?
The No Free Lunch Theorem, often abbreviated as NFL or NFLT, is a theoretical finding that suggests all optimization algorithms perform equally well when their performance is averaged over all possible objective functions.
The NFL stated that within certain constraints, over the space of all possible problems, every optimization technique will perform as well as every other one on average (including Random Search)
— Page 203, Essentials of Metaheuristics, 2011.
The theorem applies to optimization generally and to search problems, as optimization can be described or framed as a search problem.
The implication is that the performance of your favorite algorithm is identical to a completely naive algorithm, such as random search.
Roughly speaking we show that for both static and time dependent optimization problems the average performance of any pair of algorithms across all possible problems is exactly identical.
— No Free Lunch Theorems For Optimization, 1997.
An easy way to think about this finding is to consider a large table like you might have in excel.
Across the top of the table, each column represents a different optimization algorithm. Down the side of the table, each row represents a different objective function. Each cell of the table is the performance of the algorithm on the objective function, using whatever performance measure you like, as long as it is consistent across the whole table.
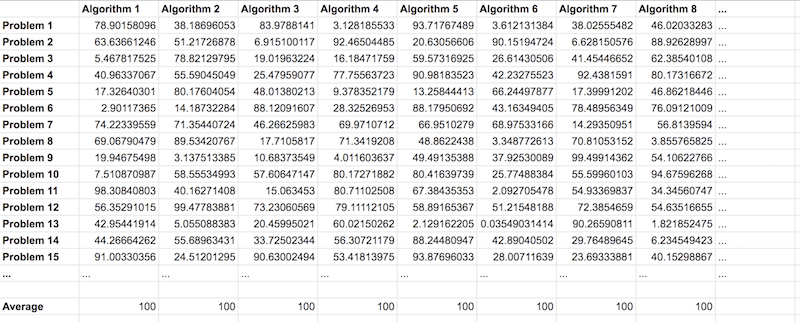
Depiction on the No Free Lunch Theorem as a Table of Algorithms and Problems
You can imagine that this table will be infinitely large. Nevertheless, in this table, we can calculate the average performance of any algorithm from all the values in its column and it will be identical to the average performance of any other algorithm column.
If one algorithm performs better than another algorithm on one class of problems, then it will perform worse on another class of problems
— Page 6, Algorithms for Optimization, 2019.
Now that we are familiar with the no free lunch theorem in general, let’s look at the specific implications for optimization.
Implications for Optimization
So-called black-box optimization algorithms are general optimization algorithms that can be applied to many different optimization problems and assume very little about the objective function.
Examples of black-box algorithms include the genetic algorithm, simulated annealing, and particle swarm optimization.
The no free lunch theorem was proposed in an environment of the late 1990s where claims of one black-box optimization algorithm being better than another optimization algorithm were being made routinely. The theorem pushes back on this, indicating that there is no best optimization algorithm, that it is provably impossible.
The theorem does state that no optimization algorithm is any better than any other optimization algorithm, on average.
… known as the “no free lunch” theorem, sets a limit on how good a learner can be. The limit is pretty low: no learner can be better than random guessing!
— Page 63, The Master Algorithm, 2018.
The catch is that the application of algorithms does not assume anything about the problem. In fact, algorithms are applied to objective functions with no prior knowledge, even such as whether the objective function is minimizing or maximizing. And this is a hard constraint of the theorem.
We often have “some” knowledge about the objective function being optimized. In fact, if in practice we truly knew nothing about the objective function, we could not choose an optimization algorithm.
As elaborated by the no free lunch theorems of Wolpert and Macready, there is no reason to prefer one algorithm over another unless we make assumptions about the probability distribution over the space of possible objective functions.
— Page 6, Algorithms for Optimization, 2019.
The beginner practitioner in the field of optimization is counseled to learn and use as much about the problem as possible in the optimization algorithm.
The more we know and harness in the algorithms about the problem, the better tailored the technique is to the problem and the more likely the algorithm is expected to perform well on the problem. The no free lunch theorem supports this advice.
We don’t care about all possible worlds, only the one we live in. If we know something about the world and incorporate it into our learner, it now has an advantage over random guessing.
— Page 63, The Master Algorithm, 2018.
Additionally, the performance is averaged over all possible objective functions and all possible optimization algorithms. Whereas in practice, we are interested in a small subset of objective functions that may have a specific structure or form and algorithms tailored to those functions.
… we cannot emphasize enough that no claims whatsoever are being made in this paper concerning how well various search algorithms work in practice The focus of this paper is on what can be said a priori without any assumptions and from mathematical principles alone concerning the utility of a search algorithm.
— No Free Lunch Theorems For Optimization, 1997.
These implications lead some practitioners to note the limited practical value of the theorem.
This is of considerable theoretical interest but, I think, of limited practical value, because the space of all possible problems likely includes many extremely unusual and pathological problems which are rarely if ever seen in practice.
— Page 203, Essentials of Metaheuristics, 2011.
Now that we have reviewed the implications of the no free lunch theorem for optimization, let’s review the implications for machine learning.
Implications for Machine Learning
Learning can be described or framed as an optimization problem, and most machine learning algorithms solve an optimization problem at their core.
The no free lunch theorem for optimization and search is applied to machine learning, specifically supervised learning, which underlies classification and regression predictive modeling tasks.
This means that all machine learning algorithms are equally effective across all possible prediction problems, e.g. random forest is as good as random predictions.
So all learning algorithms are the same in that: (1) by several definitions of “average”, all algorithms have the same average off-training-set misclassification risk, (2) therefore no learning algorithm can have lower risk than another one for all f …
— The Supervised Learning No-Free-Lunch Theorems, 2002.
This also has implications for the way in which algorithms are evaluated or chosen, such as choosing a learning algorithm via a k-fold cross-validation test harness or not.
… an algorithm that uses cross validation to choose amongst a prefixed set of learning algorithms does no better on average than one that does not.
— The Supervised Learning No-Free-Lunch Theorems, 2002.
It also has implications for common heuristics for what constitutes a “good” machine learning model, such as avoiding overfitting or choosing the simplest possible model that performs well.
Another set of examples is provided by all the heuristics that people have come up with for supervised learning avoid overfitting prefer simpler to more complex models etc. [no free lunch] says that all such heuristics fail as often as they succeed.
— The Supervised Learning No-Free-Lunch Theorems, 2002.
Given that there is no best single machine learning algorithm across all possible prediction problems, it motivates the need to continue to develop new learning algorithms and to better understand algorithms that have already been developed.
As a consequence of the no free lunch theorem, we need to develop many different types of models, to cover the wide variety of data that occurs in the real world. And for each model, there may be many different algorithms we can use to train the model, which make different speed-accuracy-complexity tradeoffs.
— Pages 24-25, Machine Learning: A Probabilistic Perspective, 2012.
It also supports the argument of testing a suite of different machine learning algorithms for a given predictive modeling problem.
The “No Free Lunch” Theorem argues that, without having substantive information about the modeling problem, there is no single model that will always do better than any other model. Because of this, a strong case can be made to try a wide variety of techniques, then determine which model to focus on.
— Pages 25-26, Applied Predictive Modeling, 2013.
Nevertheless, as with optimization, the implications of the theorem are based on the choice of learning algorithms having zero knowledge of the problem that is being solved.
In practice, this is not the case, and a beginner machine learning practitioner is encouraged to review the available data in order to learn something about the problem that can be incorporated into the learning algorithm.
We may even want to take this one step further and say that learning is not possible without some prior knowledge and that data alone is not enough.
In the meantime, the practical consequence of the “no free lunch” theorem is that there’s no such thing as learning without knowledge. Data alone is not enough.
— Page 64, The Master Algorithm, 2018.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Papers
- The Lack of A Priori Distinctions Between Learning Algorithms, 1996.
- No Free Lunch Theorems for Search, 1995.
- No Free Lunch Theorems For Optimization, 1997.
- The Supervised Learning No-Free-Lunch Theorems, 2002.
Books
- Algorithms for Optimization, 2019.
- Essentials of Metaheuristics, 2011.
- Applied Predictive Modeling, 2013.
- Machine Learning: A Probabilistic Perspective, 2012.
- The Master Algorithm, 2018.
Articles
- No free lunch in search and optimization, Wikipedia.
- No free lunch theorem, Wikipedia.
- No Free Lunch Theorems
Summary
In this tutorial, you discovered the no free lunch theorem for optimization and search.
Specifically, you learned:
- The no free lunch theorem suggests the performance of all optimization algorithms are identical, under some specific constraints.
- There is provably no single best optimization algorithm or machine learning algorithm.
- The practical implications of the theorem may be limited given we are interested in a small subset of all possible objective functions.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post No Free Lunch Theorem for Machine Learning appeared first on Machine Learning Mastery.