
Author: Jason Brownlee
Function optimization requires the selection of an algorithm to efficiently sample the search space and locate a good or best solution.
There are many algorithms to choose from, although it is important to establish a baseline for what types of solutions are feasible or possible for a problem. This can be achieved using a naive optimization algorithm, such as a random search or a grid search.
The results achieved by a naive optimization algorithm are computationally efficient to generate and provide a point of comparison for more sophisticated optimization algorithms. Sometimes, naive algorithms are found to achieve the best performance, particularly on those problems that are noisy or non-smooth and those problems where domain expertise typically biases the choice of optimization algorithm.
In this tutorial, you will discover naive algorithms for function optimization.
After completing this tutorial, you will know:
- The role of naive algorithms in function optimization projects.
- How to generate and evaluate a random search for function optimization.
- How to generate and evaluate a grid search for function optimization.
Let’s get started.

Random Search and Grid Search for Function Optimization
Photo by Kosala Bandara, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
- Naive Function Optimization Algorithms
- Random Search for Function Optimization
- Grid Search for Function Optimization
Naive Function Optimization Algorithms
There are many different algorithms you can use for optimization, but how do you know whether the results you get are any good?
One approach to solving this problem is to establish a baseline in performance using a naive optimization algorithm.
A naive optimization algorithm is an algorithm that assumes nothing about the objective function that is being optimized.
It can be applied with very little effort and the best result achieved by the algorithm can be used as a point of reference to compare more sophisticated algorithms. If a more sophisticated algorithm cannot achieve a better result than a naive algorithm on average, then it does not have skill on your problem and should be abandoned.
There are two naive algorithms that can be used for function optimization; they are:
- Random Search
- Grid Search
These algorithms are referred to as “search” algorithms because, at base, optimization can be framed as a search problem. E.g. find the inputs that minimize or maximize the output of the objective function.
There is another algorithm that can be used called “exhaustive search” that enumerates all possible inputs. This is rarely used in practice as enumerating all possible inputs is not feasible, e.g. would require too much time to run.
Nevertheless, if you find yourself working on an optimization problem for which all inputs can be enumerated and evaluated in reasonable time, this should be the default strategy you should use.
Let’s take a closer look at each in turn.
Random Search for Function Optimization
Random search is also referred to as random optimization or random sampling.
Random search involves generating and evaluating random inputs to the objective function. It’s effective because it does not assume anything about the structure of the objective function. This can be beneficial for problems where there is a lot of domain expertise that may influence or bias the optimization strategy, allowing non-intuitive solutions to be discovered.
… random sampling, which simply draws m random samples over the design space using a pseudorandom number generator. To generate a random sample x, we can sample each variable independently from a distribution.
— Page 236, Algorithms for Optimization, 2019.
Random search may also be the best strategy for highly complex problems with noisy or non-smooth (discontinuous) areas of the search space that can cause algorithms that depend on reliable gradients.
We can generate a random sample from a domain using a pseudorandom number generator. Each variable requires a well-defined bound or range and a uniformly random value can be sampled from the range, then evaluated.
Generating random samples is computationally trivial and does not take up much memory, therefore, it may be efficient to generate a large sample of inputs, then evaluate them. Each sample is independent, so samples can be evaluated in parallel if needed to accelerate the process.
The example below gives an example of a simple one-dimensional minimization objective function and generates then evaluates a random sample of 100 inputs. The input with the best performance is then reported.
# example of random search for function optimization
from numpy.random import rand
# objective function
def objective(x):
return x**2.0
# define range for input
r_min, r_max = -5.0, 5.0
# generate a random sample from the domain
sample = r_min + rand(100) * (r_max - r_min)
# evaluate the sample
sample_eval = objective(sample)
# locate the best solution
best_ix = 0
for i in range(len(sample)):
if sample_eval[i] < sample_eval[best_ix]:
best_ix = i
# summarize best solution
print('Best: f(%.5f) = %.5f' % (sample[best_ix], sample_eval[best_ix]))
Running the example generates a random sample of input values, which are then evaluated. The best performing point is then identified and reported.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the result is very close to the optimal input of 0.0.
Best: f(-0.01762) = 0.00031
We can update the example to plot the objective function and show the sample and best result. The complete example is listed below.
# example of random search for function optimization with plot
from numpy import arange
from numpy.random import rand
from matplotlib import pyplot
# objective function
def objective(x):
return x**2.0
# define range for input
r_min, r_max = -5.0, 5.0
# generate a random sample from the domain
sample = r_min + rand(100) * (r_max - r_min)
# evaluate the sample
sample_eval = objective(sample)
# locate the best solution
best_ix = 0
for i in range(len(sample)):
if sample_eval[i] < sample_eval[best_ix]:
best_ix = i
# summarize best solution
print('Best: f(%.5f) = %.5f' % (sample[best_ix], sample_eval[best_ix]))
# sample input range uniformly at 0.1 increments
inputs = arange(r_min, r_max, 0.1)
# compute targets
results = objective(inputs)
# create a line plot of input vs result
pyplot.plot(inputs, results)
# plot the sample
pyplot.scatter(sample, sample_eval)
# draw a vertical line at the best input
pyplot.axvline(x=sample[best_ix], ls='--', color='red')
# show the plot
pyplot.show()
Running the example again generates the random sample and reports the best result.
Best: f(0.01934) = 0.00037
A line plot is then created showing the shape of the objective function, the random sample, and a red line for the best result located from the sample.
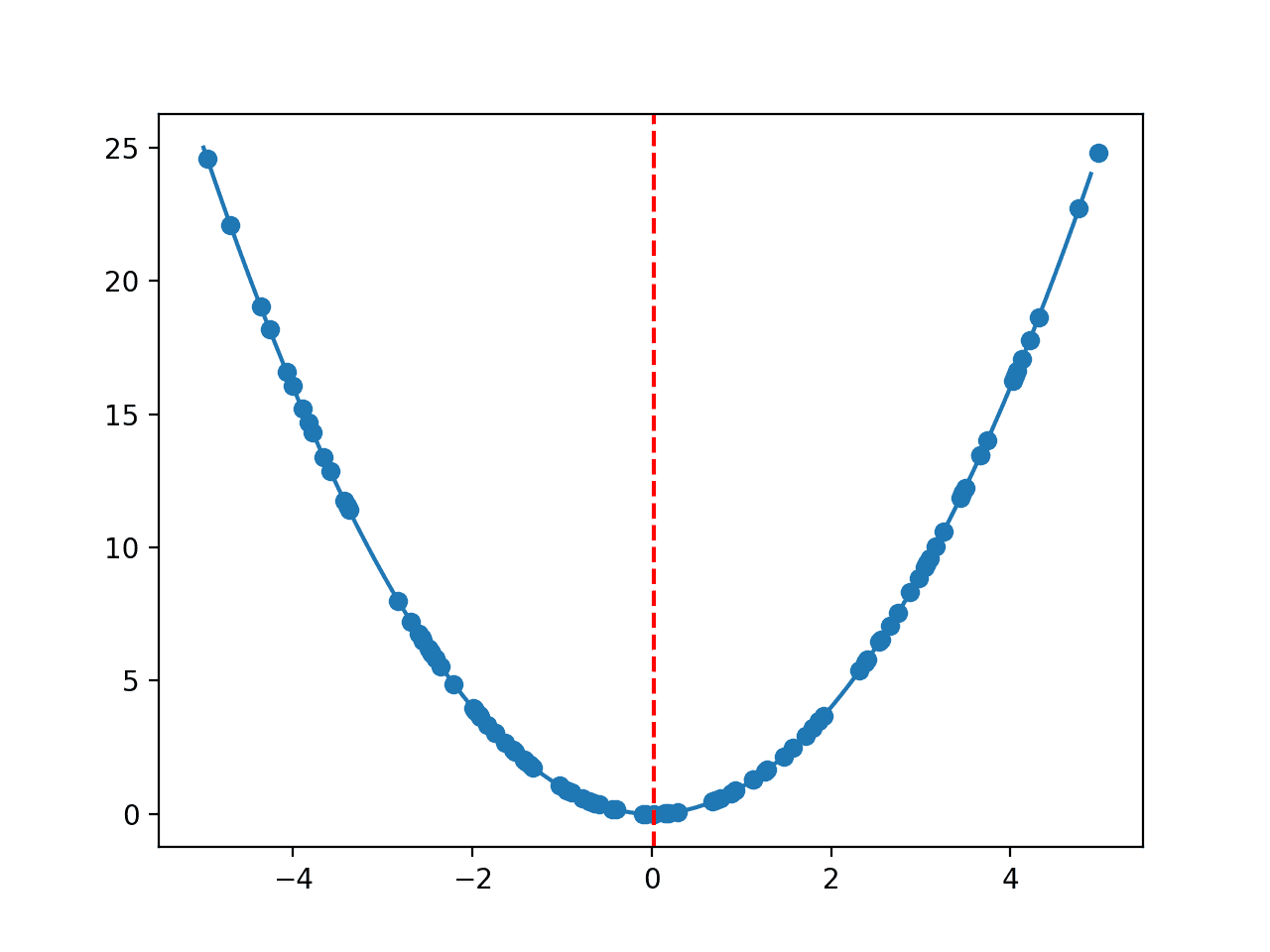
Line Plot of One-Dimensional Objective Function With Random Sample
Grid Search for Function Optimization
Grid search is also referred to as a grid sampling or full factorial sampling.
Grid search involves generating uniform grid inputs for an objective function. In one-dimension, this would be inputs evenly spaced along a line. In two-dimensions, this would be a lattice of evenly spaced points across the surface, and so on for higher dimensions.
The full factorial sampling plan places a grid of evenly spaced points over the search space. This approach is easy to implement, does not rely on randomness, and covers the space, but it uses a large number of points.
— Page 235, Algorithms for Optimization, 2019.
Like random search, a grid search can be particularly effective on problems where domain expertise is typically used to influence the selection of specific optimization algorithms. The grid can help to quickly identify areas of a search space that may deserve more attention.
The grid of samples is typically uniform, although this does not have to be the case. For example, a log-10 scale could be used with a uniform spacing, allowing sampling to be performed across orders of magnitude.
The downside is that the coarseness of the grid may step over whole regions of the search space where good solutions reside, a problem that gets worse as the number of inputs (dimensions of the search space) to the problem increases.
A grid of samples can be generated by choosing the uniform separation of points, then enumerating each variable in turn and incrementing each variable by the chosen separation.
The example below gives an example of a simple two-dimensional minimization objective function and generates then evaluates a grid sample with a spacing of 0.1 for both input variables. The input with the best performance is then reported.
# example of grid search for function optimization
from numpy import arange
from numpy.random import rand
# objective function
def objective(x, y):
return x**2.0 + y**2.0
# define range for input
r_min, r_max = -5.0, 5.0
# generate a grid sample from the domain
sample = list()
step = 0.1
for x in arange(r_min, r_max+step, step):
for y in arange(r_min, r_max+step, step):
sample.append([x,y])
# evaluate the sample
sample_eval = [objective(x,y) for x,y in sample]
# locate the best solution
best_ix = 0
for i in range(len(sample)):
if sample_eval[i] < sample_eval[best_ix]:
best_ix = i
# summarize best solution
print('Best: f(%.5f,%.5f) = %.5f' % (sample[best_ix][0], sample[best_ix][1], sample_eval[best_ix]))
Running the example generates a grid of input values, which are then evaluated. The best performing point is then identified and reported.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the result finds the optima exactly.
Best: f(-0.00000,-0.00000) = 0.00000
We can update the example to plot the objective function and show the sample and best result. The complete example is listed below.
# example of grid search for function optimization with plot
from numpy import arange
from numpy import meshgrid
from numpy.random import rand
from matplotlib import pyplot
# objective function
def objective(x, y):
return x**2.0 + y**2.0
# define range for input
r_min, r_max = -5.0, 5.0
# generate a grid sample from the domain
sample = list()
step = 0.5
for x in arange(r_min, r_max+step, step):
for y in arange(r_min, r_max+step, step):
sample.append([x,y])
# evaluate the sample
sample_eval = [objective(x,y) for x,y in sample]
# locate the best solution
best_ix = 0
for i in range(len(sample)):
if sample_eval[i] < sample_eval[best_ix]:
best_ix = i
# summarize best solution
print('Best: f(%.5f,%.5f) = %.5f' % (sample[best_ix][0], sample[best_ix][1], sample_eval[best_ix]))
# sample input range uniformly at 0.1 increments
xaxis = arange(r_min, r_max, 0.1)
yaxis = arange(r_min, r_max, 0.1)
# create a mesh from the axis
x, y = meshgrid(xaxis, yaxis)
# compute targets
results = objective(x, y)
# create a filled contour plot
pyplot.contourf(x, y, results, levels=50, cmap='jet')
# plot the sample as black circles
pyplot.plot([x for x,_ in sample], [y for _,y in sample], '.', color='black')
# draw the best result as a white star
pyplot.plot(sample[best_ix][0], sample[best_ix][1], '*', color='white')
# show the plot
pyplot.show()
Running the example again generates the grid sample and reports the best result.
Best: f(0.00000,0.00000) = 0.00000
A contour plot is then created showing the shape of the objective function, the grid sample as black dots, and a white star for the best result located from the sample.
Note that some of the black dots for the edge of the domain appear to be off the plot; this is just an artifact for how we are choosing to draw the dots (e.g. not centered on the sample).
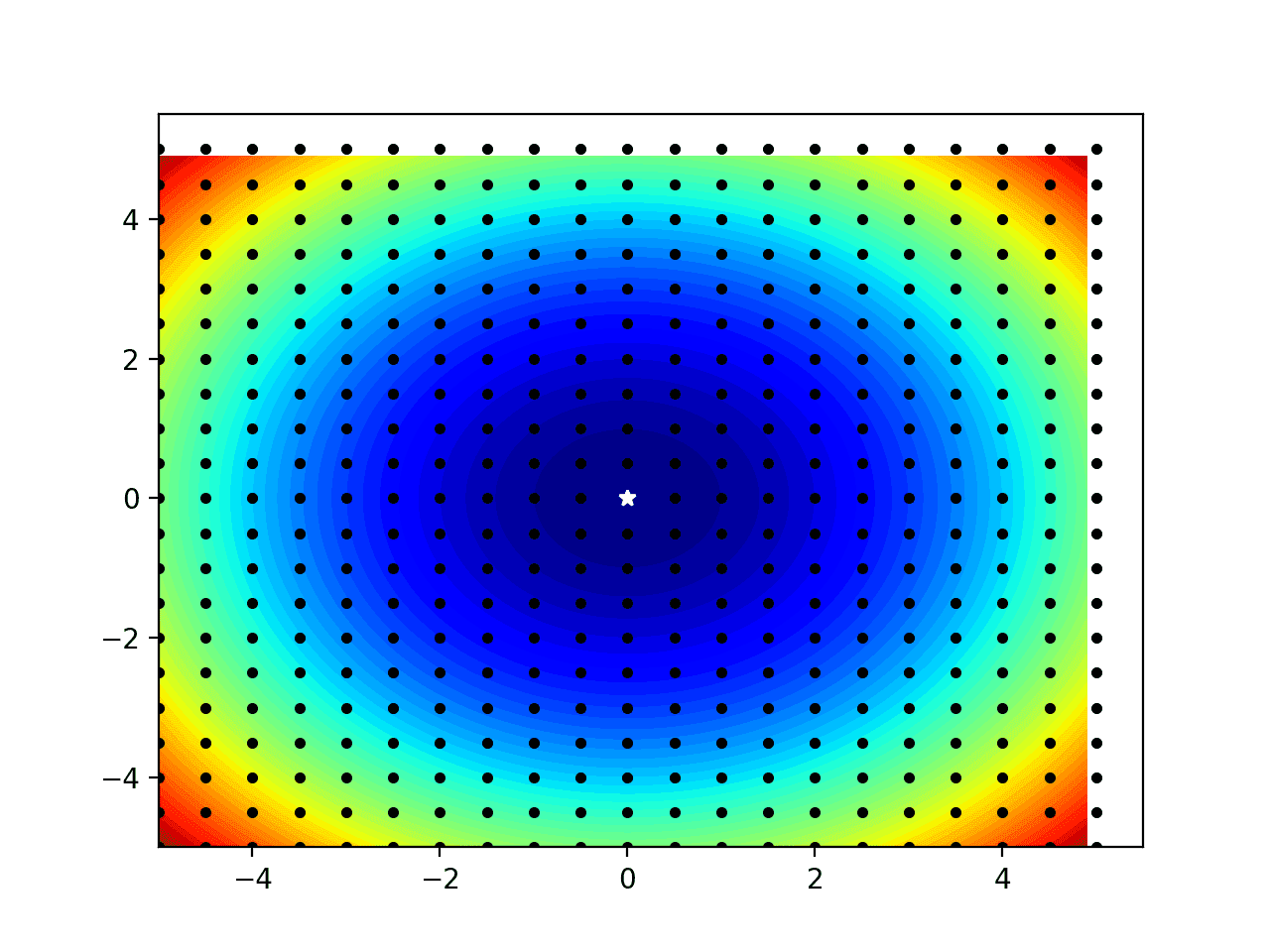
Contour Plot of One-Dimensional Objective Function With Grid Sample
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Books
- Algorithms for Optimization, 2019.
Articles
Summary
In this tutorial, you discovered naive algorithms for function optimization.
Specifically, you learned:
- The role of naive algorithms in function optimization projects.
- How to generate and evaluate a random search for function optimization.
- How to generate and evaluate a grid search for function optimization.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post Random Search and Grid Search for Function Optimization appeared first on Machine Learning Mastery.